Arquitectura kakfa
Apache Kafka es una plataforma distribuida de transmisión de datos que permite publicar, almacenar y procesar flujos de registros, y suscribirse a ellos, en tiempo real. Está diseñada para manejar flujos de datos de varias fuentes y distribuirlos a los diversos usuarios. En resumen, transfiere cantidades enormes de datos, no solo desde el punto A hasta el B, sino también del punto A al Z y a cualquier otro lugar que necesite, y todo al mismo tiempo.
Apache Kafka es la alternativa a un sistema de mensajería empresarial tradicional. Comenzó como un sistema interno que LinkedIn desarrolló para manejar 1.4 billones de mensajes por día. Ahora, es una solución open source de transmisión de datos con aplicaciones para diversas necesidades empresariales.
Integración asíncrona con Apache Kafka
Los microservicios han cambiado el panorama del desarrollo. Al reducir las dependencias, como los niveles de bases de datos compartidas, estos permiten que los desarrolladores sean más ágiles. No obstante, las aplicaciones distribuidas que diseñan sus desarrolladores aún necesitan algún tipo de integración para compartir datos. Una opción de integración popular, conocida como el método síncrono, utiliza interfaces de programación de aplicaciones (API) para compartir datos entre los diferentes usuarios.
Otra opción de integración, el método asíncrono, implica replicar datos en un almacén intermedio. Aquí es donde Apache Kafka entra en acción, una plataforma que transmite datos desde otros equipos de desarrollo para rellenar el almacén de datos, de modo que estos se puedan compartir entre varios equipos y sus aplicaciones.
Apache Kafka puede manejar millones de puntos de datos por segundo, lo cual lo hace ideal para los desafíos del big data. Sin embargo, Kafka también es importante para las empresas que no manejan escenarios de datos tan extremos en la actualidad. En muchos casos prácticos de procesamiento de datos, como el Internet de las cosas (IoT) y las redes sociales, los datos aumentan de manera exponencial y pueden sobrecargar rápidamente una aplicación diseñada en función del volumen de datos actual. En cuanto al procesamiento de datos, debe tener en cuenta la escalabilidad, lo cual implica planificar la creciente proliferación de datos.
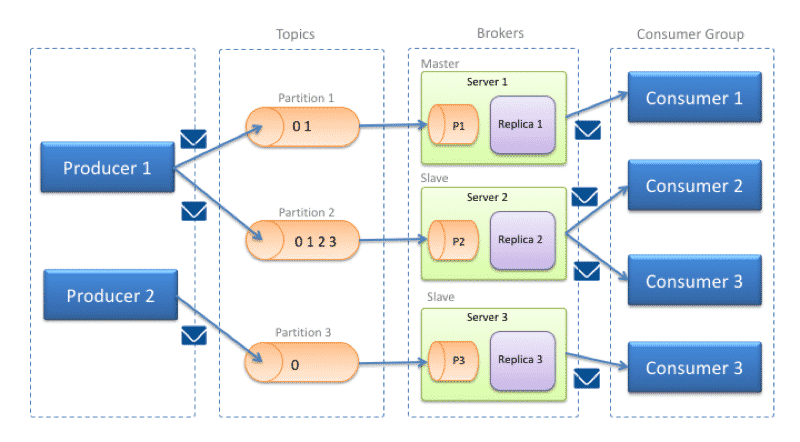
Las claves de la arquitectura de Apache Kafka
Apache Kafka se ejecuta como un clúster (red de ordenadores) en uno o más servidores que pueden encontrarse en centros de datos diferentes. Los nodos o puntos de intersección del clúster, denominados brokers, almacenan los flujos de datos entrantes, clasificándolos en los llamados topics. Los datos se dividen en particiones y se replican y distribuyen en el clúster, recibiendo un sello de tiempo. De esta manera, la plataforma de transmisión asegura una gran disponibilidad y un acceso de lectura rápido. Apache Kafka distingue los temas entre “normal topics” y “compacted topics”. Los mensajes de normal topics pueden borrarse una vez se ha excedido el período o el límite de almacenamiento, mientras que las entradas de compacted topics no están sujetas a limitaciones de tiempo ni espacio.
Para más información,
https://kafka.apache.org/25/documentation/streams/architecture